컬렉션 프레임워크란?
데이터 군을 저장하는 클래스들을 표준화한 설계를 뜻합니다. 다수의 데이터를 쉽고 효과적으로 처리할수 있게 다양하고 많은 클래스들을 제공하고 인터페이스와 다형성을 이용한 객체지향적 설계가 표준화되어 재사용성이 높은 코드를 작성할 수 있는 장점이 있습니다.
컬렉션 프레임워크 핵심 인터페이스
컬렉션 프레임워크는 컬렉션을 다루는데 필요한 주요 인터페이스를 정의하고 있습니다.
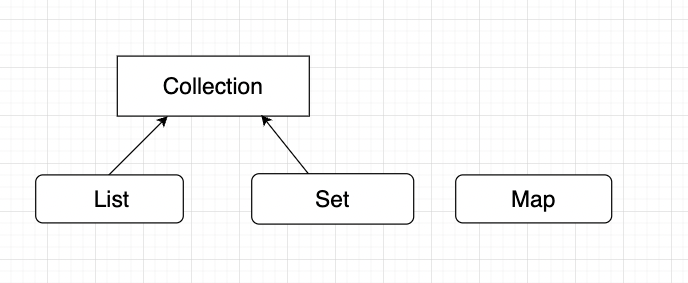
Map 인터페이스는 컬렉션 인터페이스와 다른 형태로 컬렉션을 다루기 때문에 상속 계층도에 포함되지 못하고 별도로 정의됩니다.
| 인터페이스 | 특징 |
| List | 순서가 있는 데이터의 집합, 데이터의 중복을 허용 - 구현클래스: ArrayList, LinkedList, Stack, Vector 등 |
| Set | 순서를 유지하지 않는 데이터의 집합, 데이터의 중복 허용을 하지 않음 - 구현클래스: HashSet, TreeSet |
| Map | 키(key) 와 값(value)의 쌍으로 이루어진 데이터의 집합 순서는 유지되지 않으며, 키는 중복을 허용하지 않고 값은 중복을 허용 - 구현클래스: HashMap, TreeMap, HashTable 등 |
ArrayList
컬렉션 클래스에서 가장 많이 쓰이는 ArrayList는 List를 구현하기 때문에 데이터의 저장순서가 유지되고 중복을 허용합니다.
Object 배열을 이용해서 데이터를 0번째 부터 순차적으로 저장하고 만약 배열에 더 이상 저장할 공간이 없으면 더 큰 배열을 생성해서 기존의 배열에 저장된 내용을 새로운 배열에 복사한 다음에 저장이 됩니다.
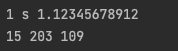
import java.util.ArrayList;
public class Example {
public static void main(String[] args) {
ArrayList a = new ArrayList();
a.add(1);
a.add("s");
a.add(1.12345678912);
ArrayList<Integer> numArr = new ArrayList<>();
numArr.add(15);
numArr.add(203);
numArr.add(109);
// numArr.add("dsd");// 에러!!
for (Object o : a) {
System.out.print(o + " ");
}
System.out.println();
for (Integer num : numArr) {
System.out.print(num + " ");
}
}
}
ArrayList 에 타입을 지정하지 않으면 기본인 Object타입으로 모든 종류의 객체를 담을 수 있습니다. 그렇지 않고 사용자가 따로 타입을 지정하여 해당 타입만 사용하는 리스트를 구현할 수 있습니다. 순차적으로 추가/삭제하는 경우에는 좋은 효율을 낼 수 있습니다.
LinkedList
배열은 크기를 변경할 수 없습니다. 크기를 변경하려면 새로운 배열을 생성하여 복사를 해야하고 순차적이지 않은 데이터의 추가 or 삭제에 시간이 많이 걸립니다. 만약 데이터를 중간에 추가하려면 빈 공간을 만들기 우해 다른 데이터들을 복사해서 이동해야 하기 때문입니다.
이러한 단점을 보완하기 위해서 LinkedList 라는 자료구조가 고안이 되었습니다. 연결리스트는 불연속적으로 존재하는 데이터들을 서로 연결(Link) 한 형태로 구성되어 있습니다.
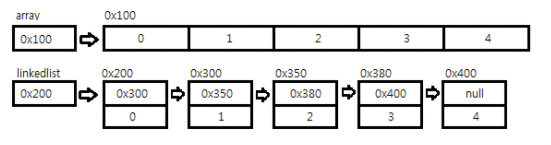
위 그림에서 알 수 있듯이 각 요소들은 자신과 연결된 다음 주소값을 참조하고있고 데이터를 가지고 있습니다.
class Node{
Node next; // 다음 요소의 주소
Object obj; // 데이터
}
하지만 연결리스트는 단방향이동이기 때문에 이전 요소에 대한 접근은 어렵습니다. 이런 단점을 보완한 것이 이중 연결리스트(Doubley Linked List)입니다. 단순히 이전값을 참조할 수 있게 노드에 참조변수 하나가 추가 되었습니다. 이중 연결리스트는 연결리스트 보다 각 요소에 대하여 접근과 이동이 쉽기 때문에 더 많이 사용됩니다.

class Node{
Node next; //다음 요소의 주소
Node previous; //이전 요소의 주소
Object obj; //데이터
}
실제로 LinkedList 클래스는 이름과 달리 링크드 리스트가 아닌 더블 링크드 리스트로 구현이 되어있습니다. 링크드리스트의 낮은 접근성을 높이기 위함입니다.
import java.util.LinkedList;
public class Example {
public static void main(String[] args) {
LinkedList list = new LinkedList();
list.add(1);
list.add("안녕");
list.add(1.343);
for (Object o : list) {
System.out.print(o + " ");
}
System.out.println();
LinkedList<Integer> numList = new LinkedList<>();
numList.add(1);
numList.add(20);
numList.add(19);
for (Integer num : numList) {
System.out.print(num + " ");
}
}
}
구현은 ArrayList와 별 차이가 없습니다. 하지만 데이터의 추가/삭제 에서는 확실하게 속도 차이가 있고, 데이터의 접근시간의 차이도 있습니다.
| 컬렉션 | 읽기(접근시간) | 추가 / 삭제 | 비 고 |
| ArrayList | 빠르다 | 느리다 | 순차적인 추가 / 삭제 에서 성능이 좋다. 비효율적인 메모리사용 |
| LinkedList | 느리다 | 빠르다 | 데이터가 많을수록 접근성이 떨어짐 |
개인적으로는 스프링 공부하면서 LinkedList 가 사용되는 것을 아직은 못보긴했지만 그래도 두개의 차이점은 알고 사용을 하면 더 효율적이고 좋은 코드를 작성할 수 있을 것입니다! 나머지 Set 과 Map 은 추후 정리 하여 포스팅 하겠습니다.
'자바 (ref. 자바의정석)' 카테고리의 다른 글
| 제네릭스(Generics) - JAVA (0) | 2022.03.10 |
|---|---|
| Set, Map - JAVA (0) | 2022.03.09 |
| Comparator 와 Comparable - JAVA (3) | 2022.03.07 |
| String 클래스 - JAVA (0) | 2022.02.24 |
| 인터페이스(interface) - JAVA (0) | 2022.02.21 |